I wrote about my dislike of reCAPTCHAs on September 6, 2021. Unsurprisingly in light of the fact that I regularly use a VPN (Mullvad), use Firefox with Arkenfox’s user.js as my primary browser, and aggressively block scripts with uBlock Origin, I see a large number of captchas. The kicker these days is that because of my script blocking configuration, I am often blocking the scripts that are required for me to complete the captcha (thus rendering nugatory some of the extension solutions that I referenced in my September 2021 article). However, when I encountered a captcha while trying to pull up a Babylon Bee link that I was including in a recently posted article, I had what turned out to be an ingenious idea. Let us examine how to use Internet Archive redirects to get around having to solve captchas.
I try to keep my browser extensions limited to those that serve a valuable purpose for one reason or another (note that I lack the technical proficiency to write my own scripts in lieu of extensions). I also limit my selection of extensions to those of the free and open source variety. On Firefox, one of my essential extensions is Mr. Armin Sebastian’s excellent Web Archives. Interestingly, Mr. Sebastian is also behind Buster, an extension specifically designed to solve Google’s reCaptchas. But in today’s post, I am discussing how to use Web Archives to circumvent captchas instead of solving them.
Web Archives allows a user to open an archived or cached version of a webpage with one click.
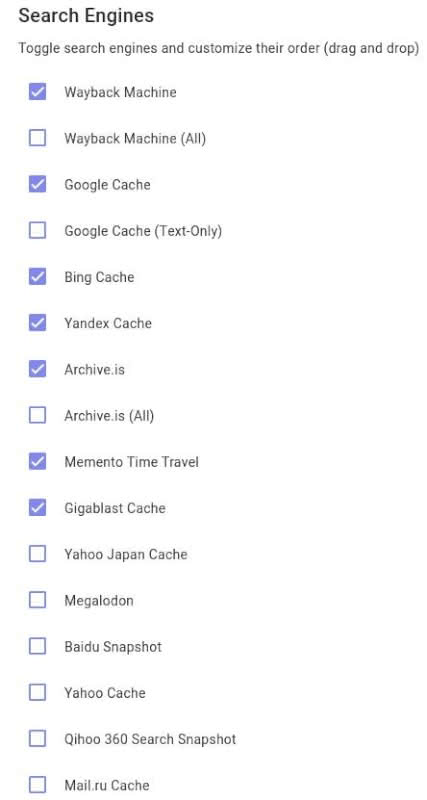
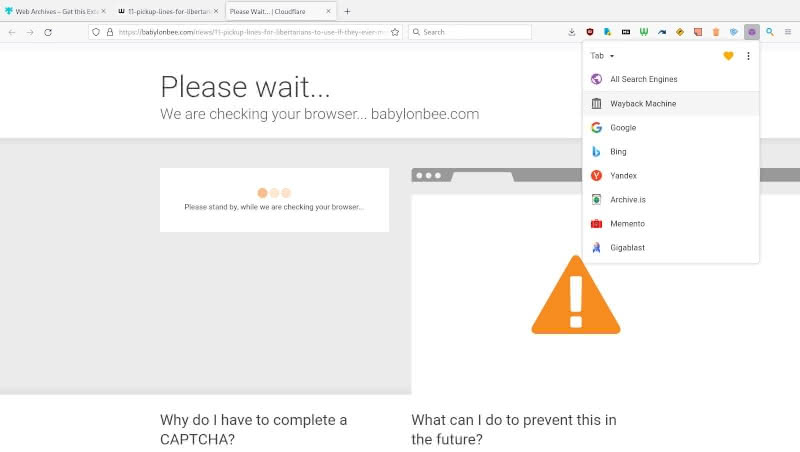
For the purpose of my captcha-busting survey, we will use the first option on Web Archives’ default list, the Internet Archive’s Wayback Machine. For this test, I will try opening up a link to the Babylon Bee article I referenced in the introduction. When I have my VPN active, I usually run into a Cloudflare captcha wall. Moreover, my script blocking settings in uBlock Origin are preventing me from completing the CAPTCHA (not that I would much want to anyway).

Instead of trying to solve the CAPTCHA (legitimately or robotically), let us open the page with the Wayback Machine using Mr. Sebastian’s handy extension.
After a few seconds, an archived version of the article from the Wayback Machine opens.
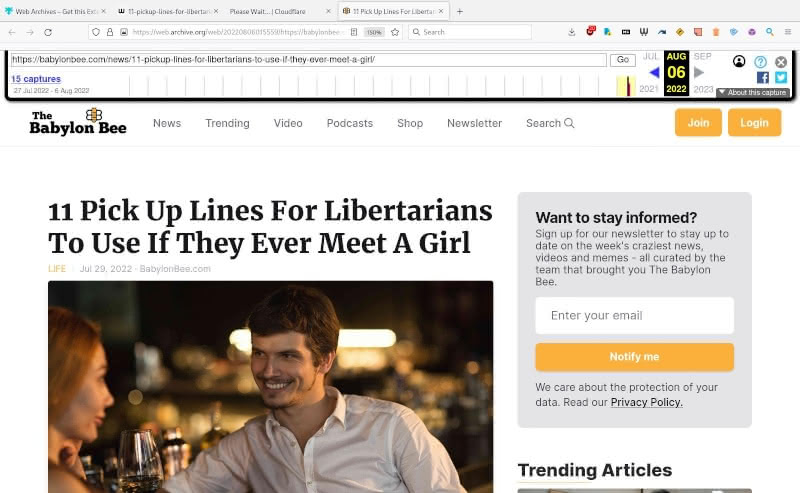
No captcha-solving needed. Note the original article is still stuck on the Cloudflare block (see the tab in the above image).
There are a few caveats and potential limitations of my newly-discovered CAPTCHA circumvention method (note: newly-discovered for me, I am sure that I am not the first person to have thought of this):
- Depending on how old the most-recently archived version of the page in question is, there may be differences between the archived page and the “current” version of the page.
- Some of the archiving/caching options may have CAPTCHAs of their own. For example, at least when I have a VPN up, I tend to run into a CAPTCHA wall with archive.is (I have not had any issues with Wayback Machine – but your mileage may vary).
- Some websites attempt to block archiving and caching of certain pages, meaning there may be cases where there is no archived or cached version of a page available.
- This method will not help at all in cases where one is trying to get to an account page or a page wherein he or she needs to input information – it is solely for reading content.
With the limitations of the archive circumvention method granted, I think that this small trick using the Web Archiver has great promise for avoiding annoying CAPTCHAs (including for people who do less to trigger them than I do). While Wayback Archive works in general for me, the plethora of archive and cache options supported by the extension makes it likely that even if one method does not work, another method will (note there is no specific requirement to use Wayback Machine in lieu of the other options). More advanced users will likely be able to write fine-tuned scripts to accomplish the same thing that I am doing through an extension.
If you have any suggestions to improve the archive-CAPTCHA circumvention method or related ideas, feel free to send me an email.