Wallabag is a free and open source bookmarking and read-it-later service which replicates some of the core functionality of Pocket. While it can be self-hosted, and I briefly hosted it on a couple of occasions, I have been using the paid Wallabag service hosted by the developers since August. I use it to save interesting articles from my feed reader and posts I encounter from around the web for reading primarily on my phone and tablet. Wallabag works well for my purposes (however, the hosted instance is a bit slow), but one issue that it does have is the inability to save certain sites. For example, some websites that use Cloudflare indirectly block Wallabag. Other sites are, for whatever reason, not amenable to saving. However, I found an end-around which works more often than not. Wallabag can save archived versions of articles from these websites from the Internet Archive’s Wayback Machine. In this post, I will offer a couple of examples of how this works in practice.
Using Internet Archive to save Tablet articles into Wallabag
Tablet magazine (https://www.tabletmag.com/) is a very good magazine with long-form opinion, news, and culture essays covering many topics. While the writing is good, there are a few things about Tablet that annoy me, chief among them is its lack of RSS and ATOM feeds.
For this example, I will use the newest post on Tablet as of the writing of this article, Ms. Maggie Phillips’s The Church of Harry (related to a topic I covered once before).
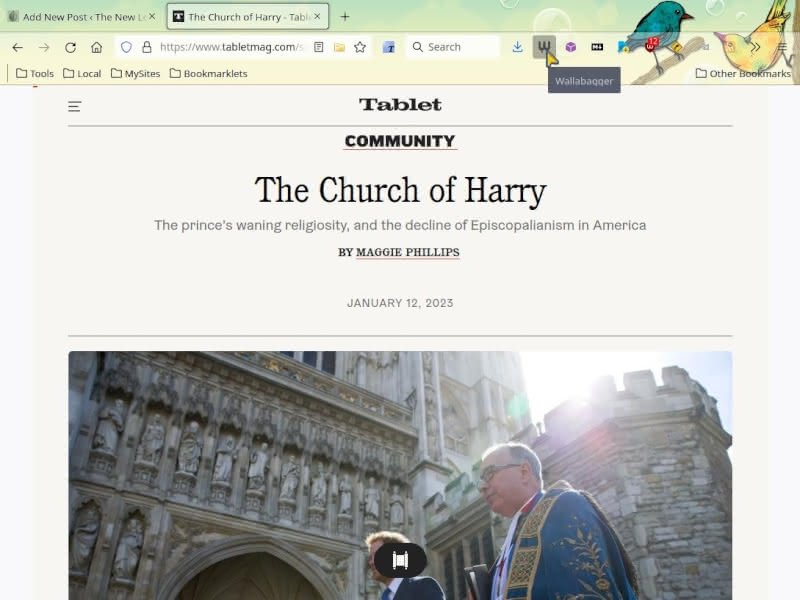
Note that my cursor is hovering over the button for the Wallabag browser extension, Wallabagger. I can save the article with one click. Let us see the result.
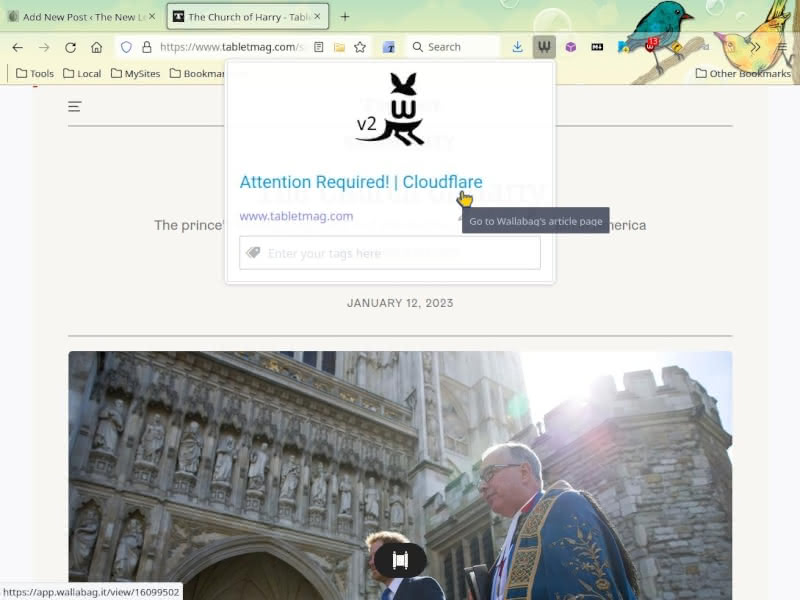
“Attention Required! | Cloudflare” is not what I saved. Sure enough, after opening the “article” in Wallabag, I find that none of the content is present.
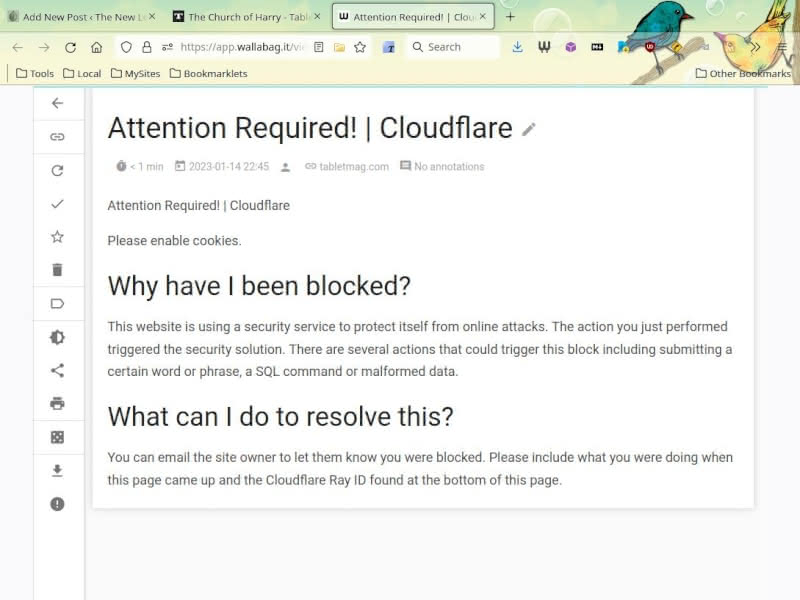
Is there no hope for saving Tablet articles to Wallabag? Fortunately, there is a way around the Cloudflare block. I previously wrote about using the Internet Archive to get around Cloudflare and CAPTCHA blocks in regular browsing. In the case of Wallabag, the same trick can help us save this Tablet article in Wallabag.
The first thing we will need to do is to retrieve a version of The Church of Harry from the Internet Archive (or submit it in the first instance if it has not already been saved). There are a number of ways to submit a URL to the Wayback Machine. I wrote a guide to creating a custom search engine shortcut in your web browser for Wayback Machine submissions a couple days before posting this article. However, for universal applicability, I will use the full submission URL. Without any additions, configuration, or navigating to another website, you can submit any URL to the Internet Archive by adding https://web.archive.org/save/ in front of the target URL. Let’s do just that for The Church of Harry.
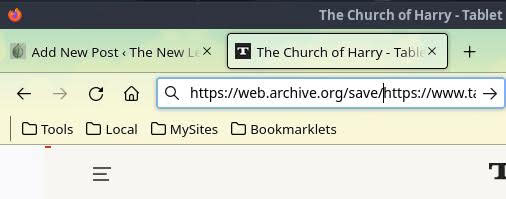
Full save URL: https://web.archive.org/save/https://www.tabletmag.com/sections/community/articles/prince-harry-church-episcopalianism
After submitting the article, we now have The Church of Harry in the Internet Archive’s Wayback Machine (note: this is sometimes a bit slow):
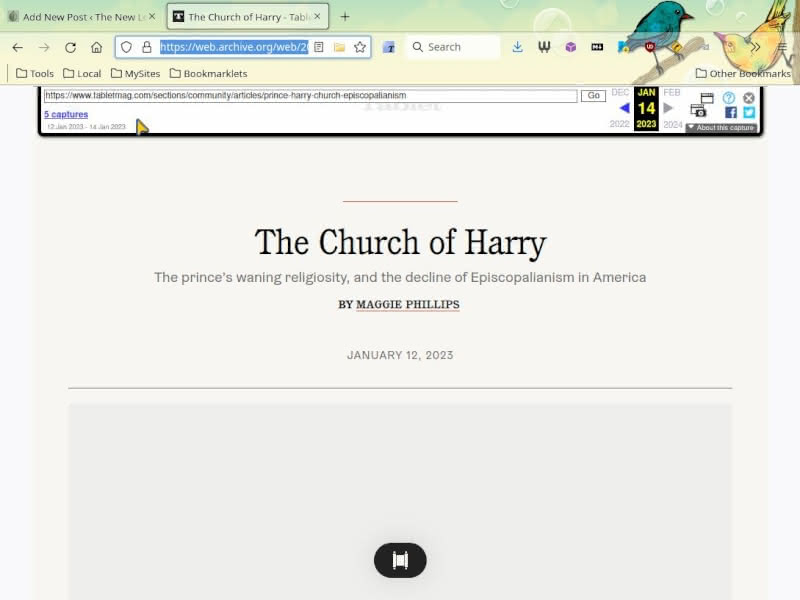
Our next step is to save the Wayback Machine version of the article into Wallabag. I will again use the Wallabagger browser extension.
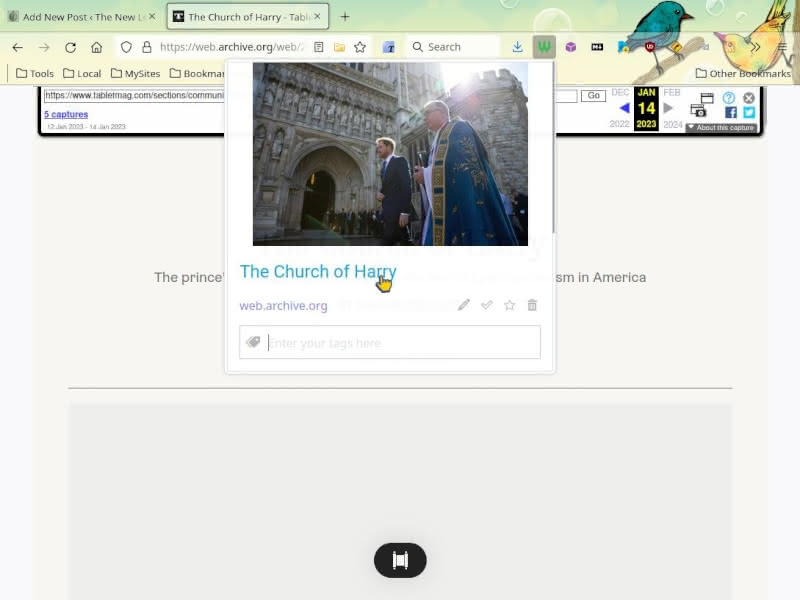
This looks promising. Instead of having a Cloudflare block as the saved article title, we have the actual title of the article with its featured image.
But was it saved correctly? Let us navigate to the saved article in Wallabag…
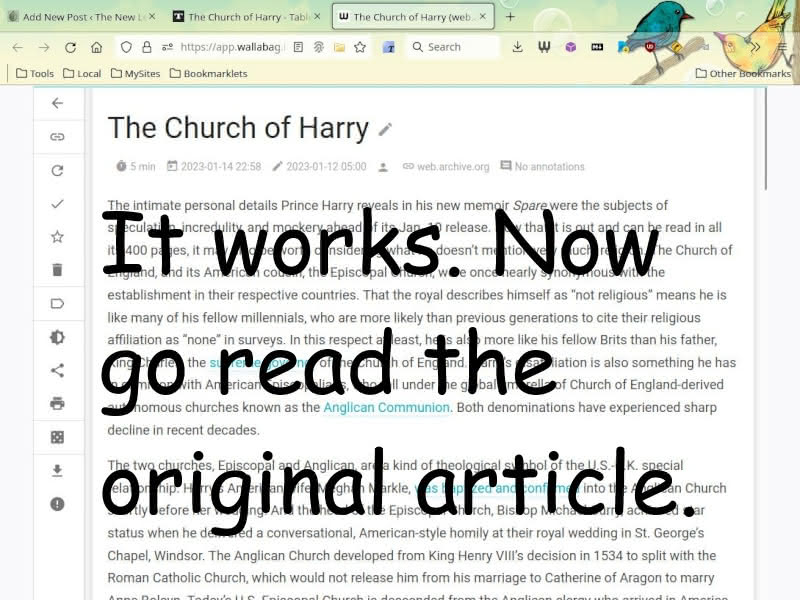
Perfect. The Internet Archive version of The Church of Harry was saved into Wallabag just as well as an article from a website that does not block is saved in the regular way.
The Internet Archive trick works perfectly for saving Tablet articles in Wallabag. However, there are a few caveats worth noting.
Firstly, this trick does not always work. For example, it usually works on Library of Congress articles (for whatever reason, Wallabag does not parse the content of the regular URLs), but the Internet Archive version occasionally does not come out “right” when saved to Wallabag (let us say something like two times out of ten). For some sites the Internet Archive trick does not work at all. However, I have found that in most cases when I could not save an article from a certain URL into Wallabag, the Internet Archive version did save correctly.
Secondly, it is important to note that all links in Internet Archive articles are to their Internet Archive versions. For example, were you to follow this link to my Welcome to The Emu Café article while reading the un-archived version of this post, it would take you to https://thenewleafjournal.com/welcome-to-the-emu-cafe/. So too would be the case if you saved this article into Wallabag. However, were you to read a version of this article from the Wayback Machine, that Emu Café link would, by default, go to its most-recently archived counterpart. You can remove the Wayback Machine part of the URL to get the original version. For my use-case, one of the best features of Wallabag or any good Read-It-Later solution is the ability to open URLs in a saved article in your Read-It-Later app. Many of the posts I read in Wallabag are links from articles that I was already reading in Wallabag. In this way, Wallabag can function as a sort of mini-internet once you save enough content. Thus, it is worth being aware of how links from Internet Archive articles behave.
What about Android?
While I save many articles into Wallabag from my computer, I almost always read the articles on a mobile device. My preferred option is my 2013 Google Nexus 7 tablet running Lineage OS (see my article on the installation), but I sometimes use my Pixel 3a XL phone, also running Lineage OS. (Note that for purposes of this section, you can consider Lineage OS indistinguishable from Android and other Android derivatives such as /e/ OS.) I often save articles into Wallabag from my mobile device, most commonly from my feed reader, but sometimes from my browser or Wallabag itself. Android makes it easy to share URLs into Wallabag from its Share context menu, but how do you first send URLs to the Wayback Machine before sending them to Wallabag?
I am sure that there are a number of ways to expeditiously share URLs to the Wayback Machine, but I chose a simple solution in a free and open source app called Url Forwarder.
Url Forwarder integrates with your device’s share menu, allowing you to forward a target URL to another URL. You can see my configuration for the Wayback Machine below:
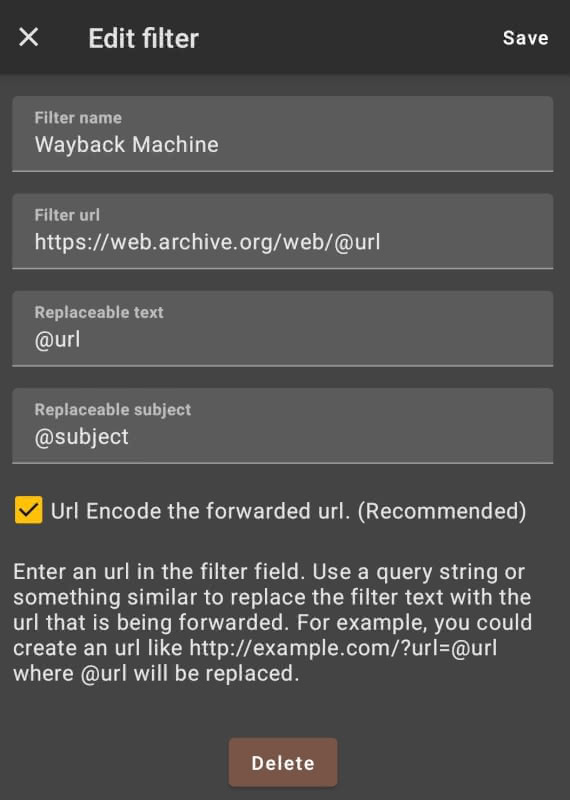
With this set-up, to send a URL to the Wayback Machine all you need to do is to first share it from your device’s share menu to Url Forwarder and then select the Wayback Machine as your filter URL.
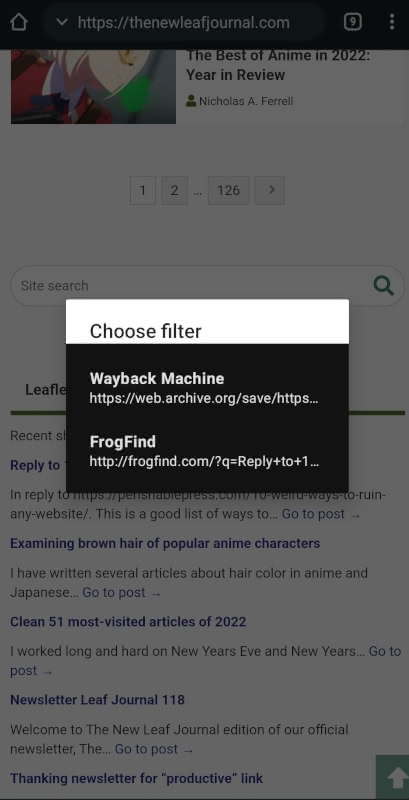
There is one note for using this with Wallabag. If your target page has previously been archived (that is, it already exists in the Wayback Machine), you can save it directly into Wallabag without first opening the link in a web browser. However, if the URL does not already exist in the Wayback Machine, trying to open it directly in Wallabag will fail. In this case, you have to first open the URL in your web browser and archive it before saving into Wallabag.
(Note: If there is a better way to configure Url Forwarder, let me know and I will update the article. For whatever reason, the URL with /save include was not working correctly for me. I figure there is a better set-up somewhere, but my simple set-up works for my limited purposes.)
Conclusion
The inability of Wallabag to index certain URLs, particularly Cloudflare pages, has been noted on at least two occasions in its GitHub forums (see issues 5423 and 5741).
While imperfect, Wallabag’s ability to archive Internet Archive URLs greatly expands its capabilities as a read-it-later and bookmarking utility. While I have only tested the Internet Archive with respect to Wallabag, you may consider applying the trick if yours is a similar service having issues parsing certain URLs.