Readers of The New Leaf Journal will know that I have used content from Project Gutenberg in many articles. For example, most posts that share the “19th Century Magazines” tag use Project Gutenberg content. Project Gutenberg is a terrific resource with one flaw: Its internal search engine is poor for anything other than searching titles (and it is not particularly good for that either). Project Gutenberg is not alone: Our own New Leaf Journal has a sub-optimal internal search engine for finding on-site content. In this post, I will demonstrate one way around both of these problems: Using the privacy-friendly DuckDuckGo search engine to search within a specific site only.
Full-Text Search in Project Gutenberg
Project Gutenberg’s default “quick search” (the search bar on its homepage) searches for books by title. It has an “advanced search” feature that allows people to craft narrower quick search queries. For my purposes, however, I often want to search the actual text of documents on Project Gutenberg. For example, if I want a neat copyright free image for an article, I am more likely to find something useful through a full text search than the taxonomy-based quick search feature. Project Gutenberg does offer three full-text search options on its search page. However, they all come courtesy of external search engines: Yahoo!, Google, and DuckDuckGo.
If you put a term in the Yahoo!, Google, or DuckDuckGo search boxes from Project Gutenberg’s search page, your query will go to the specific search engine but only search for results in Project Gutenberg. For example, a search for “pony” in the DuckDuckGo search box will have DuckDuckGo search all of the Project Gutenberg pages in its archive for the term “pony” – returning both text and image results.
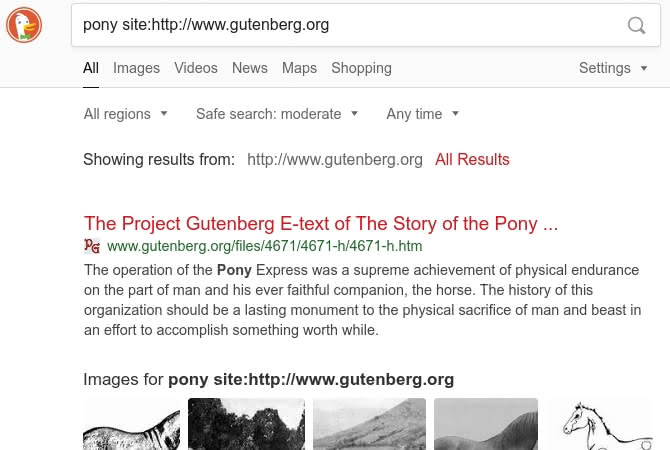
Very useful.
How to Use DuckDuckGo to Search Any Site
Project Gutenberg does not have any sort of special arrangement with Yahoo!, Google, and DuckDuckGo, nor are those the only search engines you can use for full-text searches of Project Gutenberg. Instead, Project Gutenberg added site-specific search boxes from those three search engines using functionality that is available for any site-specific search.
Below, I will show you two ways to perform a site-specific search of any site using DuckDuckGo.
Searching From Within DuckDuckGo
This method applies only if you are using a regular DuckDuckGo search box. If DuckDuckGo is your default search engine, you can use this method from the address bar or your search engine’s search box. You can also use the method if you are searching on DuckDuckGo itself.
To illustrate the correct syntax for a site-specific search on DuckDuckGo, I will search a site with which you may be (or will hopefully become) familiar: The New Leaf Journal. For this example, let us try one of our most popular search queries (according to Google, at least), “Blob Dylan.” I heard through the grapevine that someone at The New Leaf Journal has been investigating Blob Dylan graffiti, I want to quickly find that content without going through The New Leaf Journal.
I use a DuckDuckGo search box and write the following:
blob dylan site:https://thenewleafjournal.com/
The first two results are the most relevant articles for the query, in the correct order of relevancy.
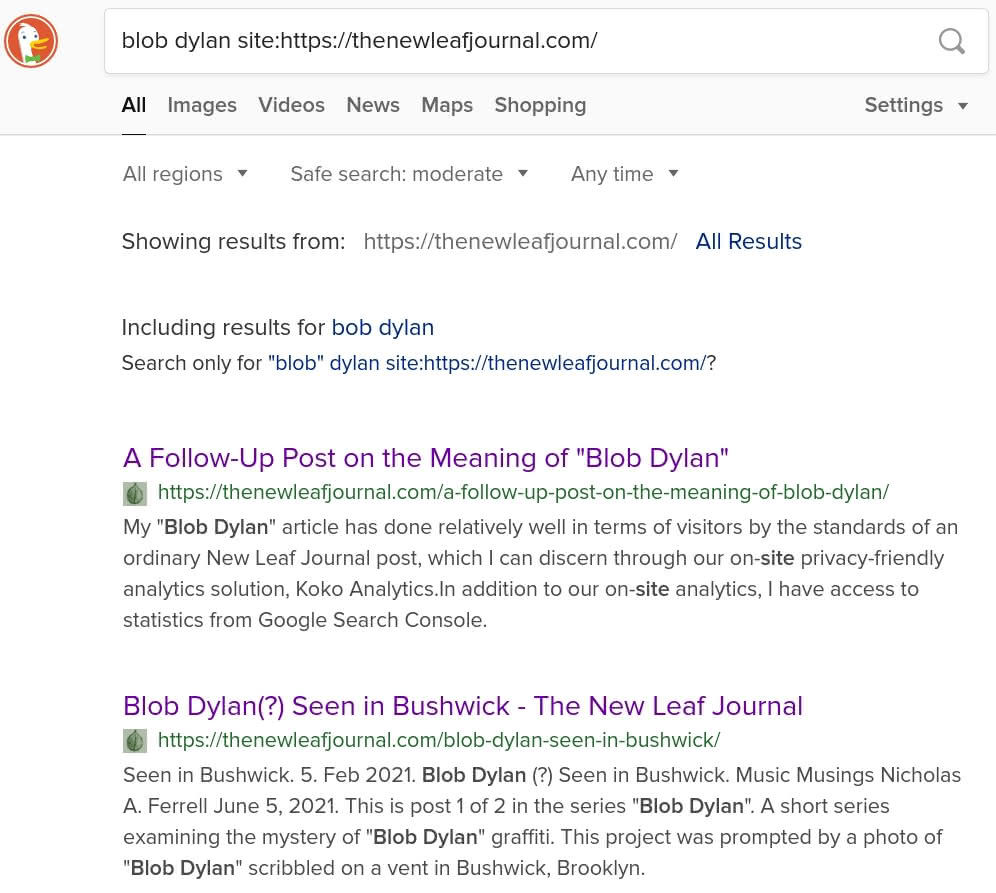
After the top two it is a bit of a mixed bag. In this case, our own internal search (at least as of August 7, 2021) returns the four most-relevant Blob Dylan results, making it a bit better than DuckDuckGo’s for one query. However, DuckDuckGo provides a plethora of advanced search options (such as sorting by date) that our built-in search does not. I have found our on-site search to be lacking in vaguer cases (e.g., try searching for “search engines” and you will find that the most relevant result – my article on alternative search engines – does not appear on the first page), so DuckDuckGo may return better results for some queries but not for others.
In all cases, the DuckDuckGo syntax is the same: query + space + site:site-url.com
Add Get-URL For Specific Site Search to Your Search Engines
In my article on alternative search engines, I discussed the process of adding search engines to a web browser (scroll down to the sub-header for the relevant section). In short, most web browsers allow users to add custom search engines in addition to the default search engines that come with the browser. This process varies by web browser, and you can look up the specific instructions for whichever browser you prefer.
In each case, adding a search engine to a browser requires the search engine’s GET URL. This works for site-specific Project Gutenberg searches with DuckDuckGo. For this example, I will use Project Gutenberg since I found it useful enough to add to my collection of custom search engines on Ungoogled Chromium.
To begin the example, let us try a specific Project Gutenberg search with DuckDuckGo. Here, I will search for “Constantine XI.”
In the DuckDuckGo search box, the query reads as follows:
constantine xi site:http://www.gutenberg.org
We do not want this query though – we want the full URL for the page displaying the results for the search. That URL is:
https://duckduckgo.com/?q=constantine+xi+site%3Ahttp%3A%2F%2Fwww.gutenberg.org&k8=%23444444&k9=%23D51920&kt=h&ia=web
In order to obtain the GET URL, we must replace the search query with %s. When you review the URL, you will see the query – “constantine+xi” – toward the beginning. We will replace that with %s to obtain the GET URL:
https://duckduckgo.com/?q=%s+site%3Ahttp%3A%2F%2Fwww.gutenberg.org&k8=%23444444&k9=%23D51920&kt=h&ia=web
If you add this URL to a search engine and then use the shortcut you assign to the URL, the “%s” will be replaced by whatever search query you use.
One Limitation of DuckDuckGo’s Site-Specific Search
DuckDuckGo’s site-specific search only includes results that are in DuckDuckGo’s index. As I noted in my article on alternative search engines, DuckDuckGo draws most of its search results from Bing so, in general, if a site is indexed on Bing, it will also be part of DuckDuckGo’s index. With a few exceptions that I designated “no index,” all of our content is listed in Bing’s search index – and all of those articles are discoverable on DuckDuckGo.
Other Search Engine Options
Other search engines also allow users to search by specific sites, including both Google and Yahoo! If you prefer a different search engine to DuckDuckGo, you may look to find whether it supports site-specific searches and the instructions for how to perform them.
Another Full-Text Gutenberg Search Tool: Gutensearch
For those who are interested specifically in full-text Project Gutenberg searches, there is a new and interesting search engine called Gutensearch. You can see its GitHub repository and public search website.
I have not tested it too much yet, but it does have some advantages over DuckDuckGo. For example, it displays long excerpts from the results it returns to give a clear idea of what they include. Thus, when I try a search for “constantine xi,” I can quickly see which results have content about his struggle to defend Constantinople in 1453 and which results merely include his name on a timeline of Byzantine emperors or in a short encyclopedia entry. It also includes a search feature that returns random results instead of those that the algorithm deems to be most relevant.
However, at the moment, it does not have search-specific URLs, so lest I am missing something, there is no way to use Gutensearch without self-hosting or (for most users) visiting Gutensearch’s website. Furthermore, unlike DuckDuckGo, it is not possible to use Gutensearch to search for images.
Final Thoughts
Many sites have search engines that are somewhat lacking in precision and features. The ability to use DuckDuckGo (or another full-featured search engine) to search these sites can be valuable. The DuckDuckGo site-specific search for Project Gutenberg is useful to my workflow in creating New Leaf Journal content. Furthermore, in some cases, DuckDuckGo may provide more useful results for The New Leaf Journal than our own search engine – which uses WordPress’s default search with a few additional features – can deliver. The method I demonstrated in this article should work for using DuckDuckGo on any site that has its results indexed by Bing or Yandex.