Today I will offer a quick introduction to, and review of, FrogFind. FrogFind’s tagline describes it as “The Search Engine For Vintage Computers.” Lest this ambiguous headline lead to confusion, which it did when FrogFind was featured on Hacker News, FrogFind is a search engine designed for use on vintage computers, not for finding vintage computers. What does this mean? Does it have use outside of very old computers? Read on to find out.
(Note: Readers who are disappointed that FrogFind is not a search engine for finding vintage computers may enjoy my review of an AmigaOS-inspired theme for the XFWM4 window manager – seen in the above screenshot.)
What is FrogFind?
In the following subsections, I will follow the content of the FrogFind About page to explain why FrogFind was created and how it works under the hood. You can see the original About Page at the below links:
What is the Purpose of FrogFind?
FrogFind is a search tool developed by a vintage computer enthusiast named Sean who goes by Action Retro on his popular YouTube channel. Mr. Action Retro does not only collect vintage machines, he enjoys “try[ing] to get them online.” However, Action Retro explained that getting very old computers online is often easier said than done:
[T]he modern internet is not kind to old machines, which generally cannot handle the complicated javascript, CSS, and encryption that modern sites have.
While modern web design and encryption is beyond the scope of some ancient hardware, these old computers are still capable of browsing the internet. Action Retro created FrogFind as a way to make the internet amenable to the computers of yesteryear:
I decided to see how much of the internet I could turn into basic websites, so that old machines can browse the modern internet yet again!
Action Retro noted that he specifically developed FrogFind “with classic Macs in mind.” Lest you think he meant the kind of “classic Mac” that I installed Bodhi Linux on my colleague Victor V. Gurbo’s 2007 MacBook, he means something much older. Action Retro tested FrogFind on his Apple Macintosh SE/30. which was manufactured from 1989-1991. Most of his testing was done on the very modern Netscape 1.1N and 2.0.2 browsers.
How Does FrogFind Work?
Action Retro describes FrogFind as being “basically a custom wrapper for DuckDuckGo search.” It converts the results page for a query into “extremely basic HTML that old browsers can read.” What makes FrogFind particularly interesting, however, is not how it presents search results, but instead how it processes search results. Action Retro explains:
When clicking through to pages from search results, those pages are processed through a PHP port of Mozilla’s Readability, which is what powers Firefox’s reader mode. I then further strip down the results to be as basic HTML as possible.
While I am neither a programmer nor a coder, I will do my best to explain this for the broader audience. HTML is a simple markup language that can be written in a basic text editor. Markdown, which I have written about here at The New Leaf Journal, is another simple markup language (but even simpler than HTML). HTML is the foundation of web pages, but most modern websites also have CSS (for styling), JavaScript, and other scripts and elements. The more you add to a web page, the heavier it becomes and the less amenable it is to very old hardware (or low-powered hardware generally, regardless of age). FrogFind works to reduce the web – both search results and pages clicked on from those results – to simple HTML insofar as possible, leaving the reader with text and nothing else. Action Retro notes that FrogFind uses version of Firefox’s “readability mode” – which presents web pages as text without styling. Some other browsers and extensions offer similar functionality. Most full-text feed readers can also present articles in this way.
FrogFind in Action
I do not have any ancient computers to test FrogFind on, so I will instead show you how it works in practice on my main workstation, which falls well within the modern category. For these tests, I will use the BadWolf web browser because it is pleasantly uncluttered and good for taking screenshots. Note that one recommended use for FrogFind is with text-based web browsers (e.g., Lynx), but I have never used a text-based web browser and I do not have any immediate plans to change that.
Let’s try searching for my colleague, Victor V. Gurbo, in FrogFind:

I zoomed out a touch to get the first five results in the image. As you can see, FrogFind’s search result page is extremely minimal. It also strips out DuckDuckGo’s ads – which typically appear above the search results. For our first test, let us visit my article on Victor’s June 2 show at Carnegie Hall here at The New Leaf Journal:
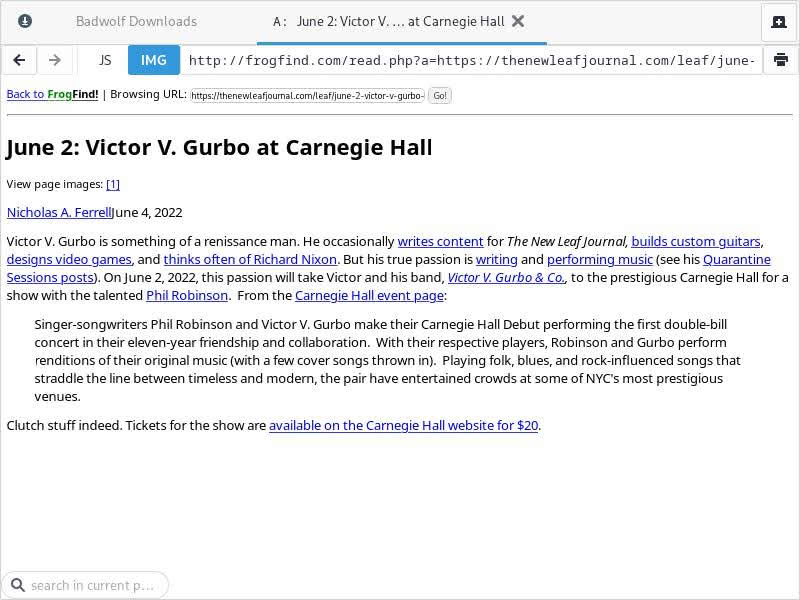
As you can see, it renders our page in simple HTML. It also strips out additional elements such as our recommended articles, images, and styling. However, note that the URL in the address bar. The URL for our page on The New Leaf Journal is (https://thenewleafjournal.com/leaf/june-2-victor-v-gurbo-at-carnegie-hall/). FrogFind renders it as (http://frogfind.com/read.php?a=https://thenewleafjournal.com/leaf/june-2-victor-v-gurbo-at-carnegie-hall/). This would seem to explain how FrogFind presents the page in readability mode and how it presents it without HTTPS encryption.
What happens if we follow a link in the page? Let’s try following the “thinks often of Richard Nixon” link first.
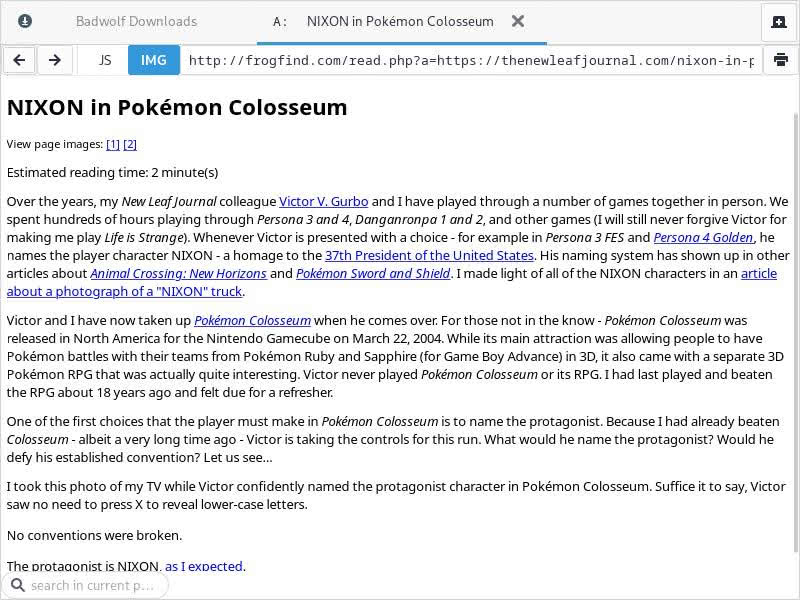
This link goes to my article on Victor naming the protagonist in Pokémon Colosseum “RICHARD NIXON.” The first thing you will note is that following an external link leads you to the FrogFind version of the link. But I followed this specific link for a reason. Now note that under the title the text reads “View page images” with links to two images. Let us try the first link.
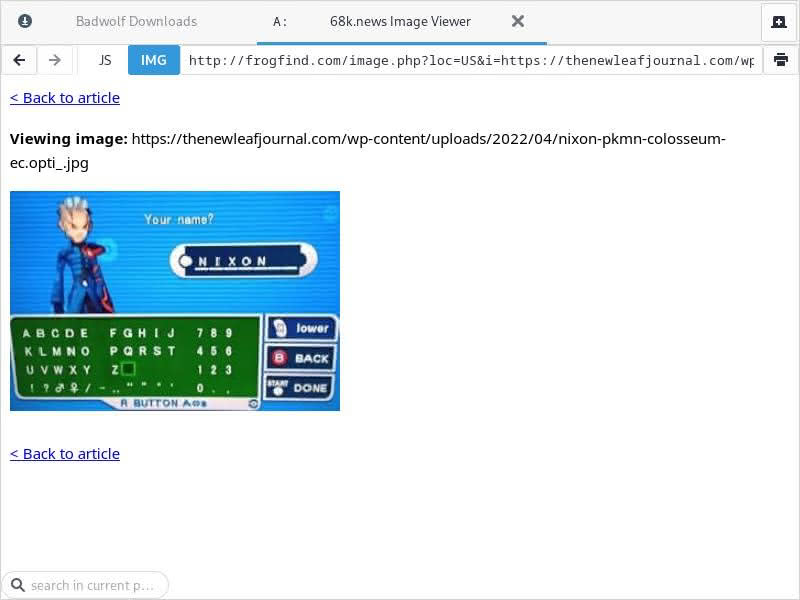
Note that I zoomed back in here. FrogFind presents links to images in the article. Here you can see the featured eyecatch image for the article (note the image URL). The second image link goes to the image I used in the body of the article (a larger version of the eyecatch). Observe that FrogFind does not show where inline images occur in the article – thus while a visitor could see the image I used in the NIXON article, it may not be clear where I used the image in the article.
Now let us return to the Carnegie Hall page and try a more complicated link – this one to Victor V. Gurbo & Co. This link goes to Victor’s official website. Victor’s site is built with Wix and is more of a portfolio-type site than a blog, meaning it is heavy on images and dynamic elements but low on text. How does FrogFind handle that? Interestingly, I could not follow the link from my article, nor could I follow the last two links on the page to Phil Robinson’s Linktree or the official Carnegie Hall event page for the show. It appears that FrogFind can follow links to the same domain from within a webpage, but not links to different domains (it only follows links to different domains from the main search results page). I was able to reach Victor’s website from the main search result page for “victor v gurbo” – where it is the first result:
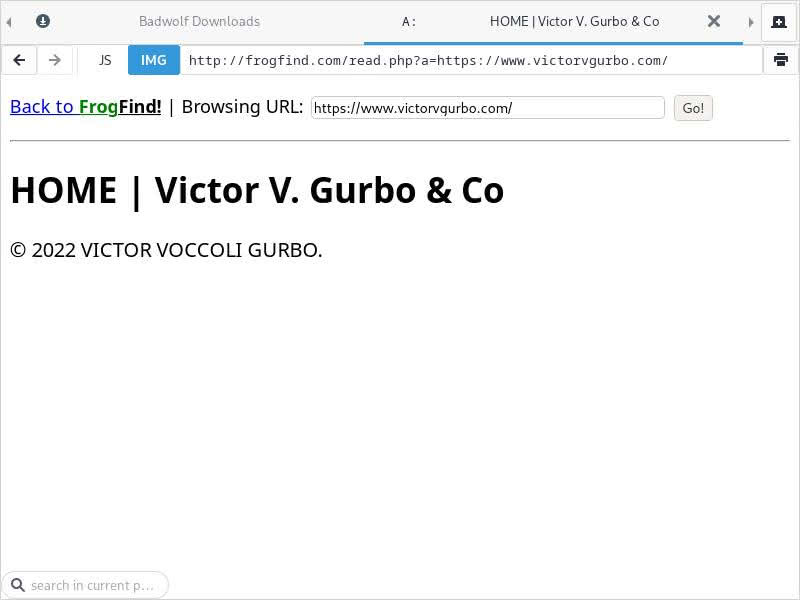
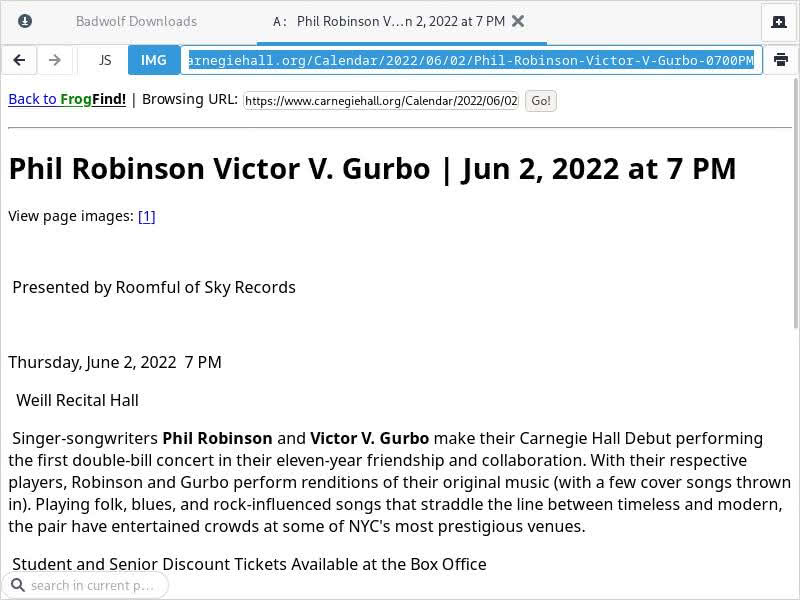
As expected, FrogFind cannot do much with Victor’s official website – by design, his homepage is not reducible to simple HTML. The same applies to his official YouTube page (second result). However, the presentation of the official event page for the concert that Victor had at Carnegie Hall with Phil Robinson was accessible from the main result page and the result was acceptable:
Trying FrogFind on an E-Reader
Having gotten to the bottom of FrogFind on my desktop, I thought of a more apt use-case for it. My desktop, which has a modern CPU and 32 GB of RAM, is not in dire need of a solution like FrogFind, especially since I do not use text-based browsers. I regularly activate FireFox’s reading mode, upon which FrogFind’s rendering is based, for reading articles without the clutter (not to mention I have a very aggressive uBlock Origin set-up for script-blocking). I do have one device where FrogFind could come in handy, however, my PocketBook Color e-reader. Now I do not regularly browse the internet on my PocketBook Color – in fact, I usually do not have it connected to the internet at all. My brief forays onto the internet with it went about as well as one would expect – it can handle very basic web tasks but would be intolerable for heavy internet-use. It was a bit less bad than trying to use my BlackBerry Classic’s web browser, however (I briefly considered trying FrogFind on my BlackBerry Classic but decided that the idea of opening that web browser was too dark).
(I apologize in advance for the poor quality of the pictures of my PocketBook instead of screenshots – but since this is a review of FrogFind and not of my e-reader, I decided to spare myself the additional steps involved with clearer images.)
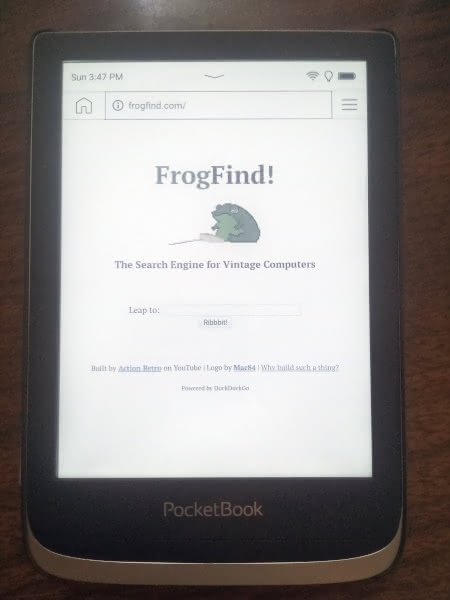
We are in. I will say that the FrogFind loaded very quickly on my under-powered browser. Let us search for a classic New Leaf Journal article.

Number one result. Just where we want to be. The search results loaded a bit more slowly than the homepage, but let us see how my article looks.

It looks excellent on my e-reader but for one issue. FrogFind does not indicate that there are images in the article. I found the same behavior on the desktop version too. I am not sure what about the Constantine XI article led to images not being recognized – but it seems like images do not work for all posts. As proof that the PocketBook versions of FrogFind sites do have the same functionality, see the image links in another post:

Now using the Welcome to the Emu Café post as an example, let us see how the regular (non-FrogFind) version of that article works on PocketBook:

Not half-bad, and the header menu works too:
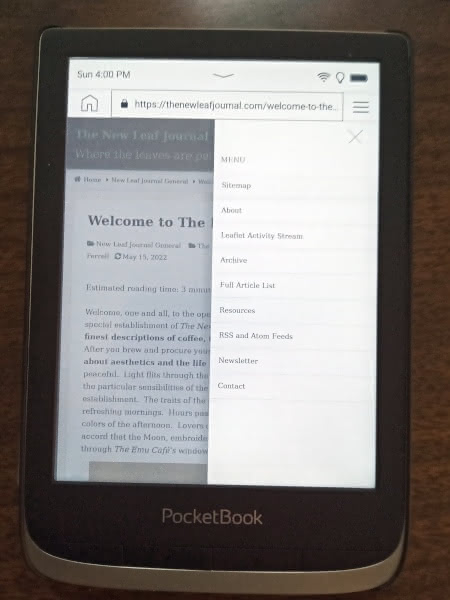
The New Leaf Journal is designed to be relatively light-weight and not dependent on JavaScript, so it performs fairly well on my PocketBook browser despite being a modern WordPress site. But were I to have to actually read the Emu Cafe article on my PocketBook, I would prefer the FrogFind version for presenting just the text – it is not as if I would want to try navigating The New Leaf Journal menus on a PocketBook .
FrogFind Search URL
In my articles on alternative search engines and Mr. Jeff Starr’s excellent Wutsearch Search Engine Launchpad, I explained that you can add search engines to most browsers and assign them search shortcuts. That is, web browsers usually come with a list of default search engines. In most cases, the default is Google, but I have seen search engines where the default is DuckDuckGo (usually on Linux) and one instance where the default was Yahoo! (not good, not the best). Microsoft Edge ships unsurprisingly with Bing as the default search engine. However, users can easily add default search engines to Chromium-based search browsers (I found that Brave, Chromium, and Vivaldi automatically add any used search engine or on-site search to the list of search engines) and Firefox (either by using Firefox’s search bar – note that is distinct from searching from the address bar, or via an extension). I will leave it to users to find out how to add search engines for their particular browsers, but in every case, you need a special URL wherein you take the search engine’s search URL and replace the query with %s.
In the case of FrogFind, the URL that you must add to set it as a stored (or default) search engine in your browser is: http://frogfind.com/?q=%s
Another Use-Case For FrogFind
While testing FrogFind, I thought of another interesting use-case for it. The way that FrogFind renders web pages is terrific for (1) printing, (2) saving an HTML version of the webpage, and (3) saving a PDF of a webpage. In all three cases, if your only concern is the text on a webpage, FrogFind’s rendering is often superior to a raw copy of the page. (Have a look at SingleFile – a great tool for saving and annotating HTML versions of webpages.)
A Brief Run-Down of Issues
I did come upon two issues in my brief FrogFind testing. Firstly, there were a few occasions where the search results did not display immediately. For example, when I searched for “constantine xi last stand” – I needed to refresh the page twice to get the results (it initially displayed the results page but with no results). Second, it did, for whatever reason, not provide image links in my Constantine XI article – but I do not know why that was the case. In any event, FrogFind is not going to be effective for webpages that rely on images, so that inconsistency, while worth fixing if possible, is not a serious issue given FrogFind’s practical use-case.
Finally, FrogFind, by design, does not use an encrypted connection. That is why all FrogFind links are http instead of https. While this makes FrogFind old-computer friendly, it will also trigger a warning in your browser if your browser is set to warn you before visiting a webpage that is not using an encrypted connection. I have set my primary browsers of the moment, Firefox and Brave, to send such a warning. However, I do not think that the http warning is the default behavior for most browsers.
Some Alternatives to FrogFind
While reviewing FrogFind, I thought of three alternatives that may satisfy some similar use cases. I may write about these alternatives in their own right in the future.
The first alternative was recommended in the Hacker News thread on FrogFind. The Old Net – which allows users to search for a site as at appeared in any year from 1994-2010 and allows for direct searches in several archives, Wikipedia, and FrogFind. There is also a lite version for low-powered hardware.
Wiby is a small-web search engine with an index that focuses on simple HTML, non-commercial websites. My favorite small-web search engine is Marginalia, which also focuses on older, non-commercial sites. Both of these search engines use encrypted connections, but many of the sites in their indexes are lightweight and old computer-friendly. I personally find both useful on any computer for discovering content that is not easy to find in mainstream search engines (I used Marginalia to good effect in my article in a 1999 Pokémon urban legend).
Conclusion
FrogFind is a neat little tool that primarily covers three use-cases: web browsing on very old computers, web browsing on low-powered devices such as e-readers, and browsing in terminal-based or text-based browsers. It also has a niche use-case for saving clean PDF and HTML versions of webpages, which is the best use-case for me personally. Although I do not think that FrogFind is particularly useful on modern hardware, some users may enjoy the very minimalist browsing experience without having to trigger an extension or browser feature for reading mode. Although FrogFind has a few quirks, it generally worked as expected in my limited testing.
That FrogFind is a wrapper for DuckDuckGo is a good thing. While one’s mileage with DuckDuckGo may vary depending on use-case or other points, it is functional as a primary search engine (relying mostly on Bing’s index) and it is usually not difficult to find ordinary results. While there could be a case for basing FrogFind on a small-web search engine, its purpose appears to be more to bring a general internet browsing experience to old hardware.
Before concluding, I will recommend that Action Retro add a privacy policy to FrogFind, especially in light of the fact that it could function as a primary (or exclusive) web browser in specialist use-cases. See my review of Peekier for an example of a strong privacy policy in another hobbyist search tool.